Linear Regression
Published on: September 29, 2020
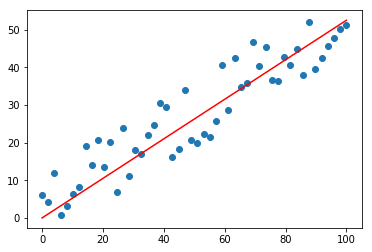
Table of Content
What is Linear Regression?
In statistics, linear regression is a linear approach to modelling the relationship between a dependent variable(y) and one or more independent variables(X). In linear regression, the relationships are modeled using linear predictor functions whose unknown model parameters are estimated from the data. Linear Regression is one of the most popular algorithms in Machine Learning. That’s due to its relative simplicity and well known properties.
The best fit line can be calculated in multiple different ways including Least Squares Regression and Gradient Descent. In this guide we'll focus on using gradient descent since this is the most commonly used technique in Machine Learning.
Simple Linear Regression
Linear Regression is called simple if you are only working with one independent variable.
Formula:
Cost Function
We can measure the accuracy of our linear regression algorithm using the mean squared error (mse) cost function. MSE measures the average squared distance between the predicted output and the actual output (label).
Optimiztation
To find the coefficients that minimize our error function we will use gradient descent. Gradient descent is a optimization algorithm which iteratively takes steps to the local minimum of the cost function.
To find the way towards the minimum we take the derivative of the error function in respect to our slope m and our y intercept b. Then we take a step in the negative direction of the derivative.
General Gradient Descent Formula:
Gradient Descent Formulas for simple linear regression:
Multivariate Linear Regression
Linear Regression is called multivariate if you are working with at least two independent variables. Each of the independent variables also called features gets multiplied with a weight which is learned by our linear regression algorithm.
Loss and optimizer are the same as for simple linear regression. The only difference is that the optimizer is now used for any weight (
Normal Equation
Another way to find the optimal coefficients is to use the "Normal Equation". The "Normal Equation" is an analytical approach for finding the optimal coefficients without needing to iterate over the data.
Contrary to Gradient Descent, when using the Normal Equation, features don't need to be scaled. The Normal Equation works well for datasets with few features but can be slow as the number of features increases due to the high computational complexity of computing the inverse
Further readings:
- Lecture 4.6 — Linear Regression With Multiple Variables | Normal Equation — [Andrew Ng]
- Derivation of the Normal Equation for linear regression
Regularization
Regularization are techniques used to reduce overfitting. This is really important to create models that generalize well on new data.

Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. For Linear Regression we can decide between two techniques – L1 and L2 Regularization.
For more information on the difference between L1 and L2 Regularization check out the following article:
You can add regularization to Linear Regression by adding regularization term to either the loss function or to the weight update.
L1 regularization:
L2 regularization:
ElasticNet
ElasticNet is a regularization technique that linearly combines the L1 and L2 penalties.
Resources:
Polynomial Regression
Polynomial Regression is a form of regression analysis that models the relationship between the independent variables
Resources:
Code
- Simple Linear Regression
- Multivariate Linear Regression
- Lasso Regression
- Ridge Regression
- ElasticNet
- Polynomial Regression
- Linear Regression Explained