Gradient Descent
Published on: May 2, 2021
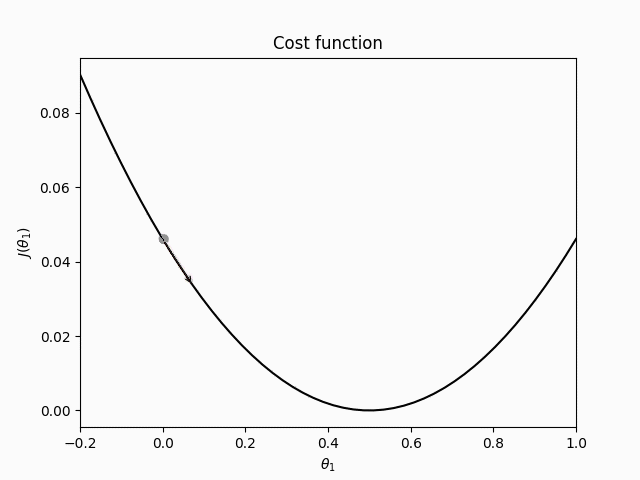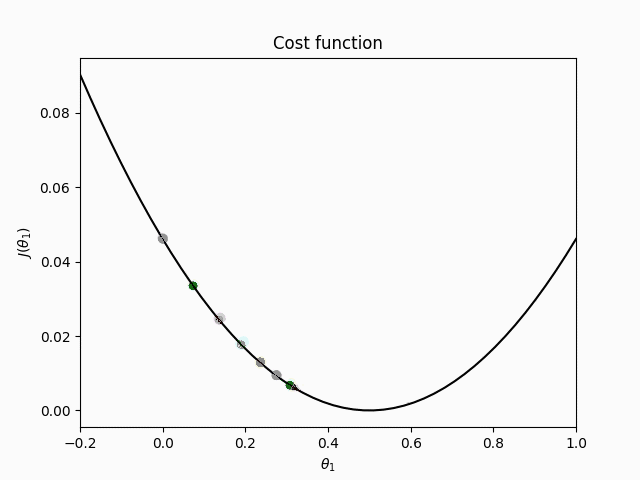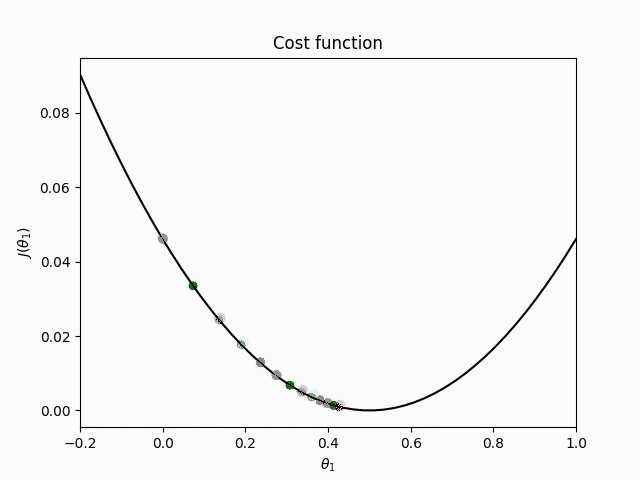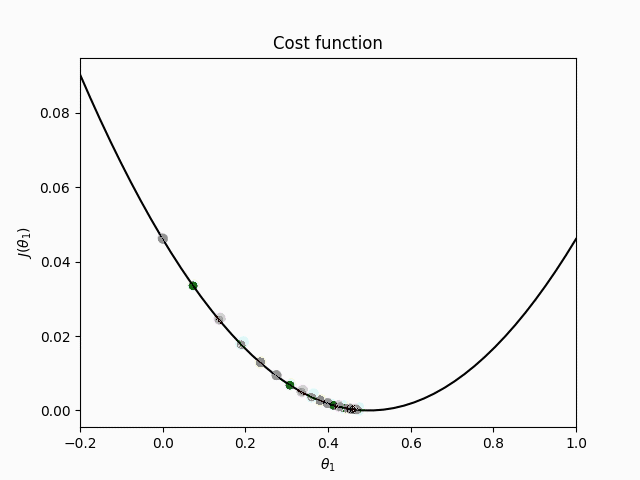
Table of Content
Gradient descent is an optimization algorithm. Optimization refers to the task of minimizing/maximizing an objective function
Picking a proper value for the learning rate

Gradient descent variants
There are three variants of gradient descent. They differ in the amount of data that is used to compute the gradient of the objective function. Depending on the amount of data, there is a trade-off between the accuracy of the parameter update (weight update) and the time it takes to perform an update.
Batch gradient descent
Batch gradient descent computes the gradient of the objective function / cost function
As all the gradients for the whole data-set need to be calculated to perform one single update, batch gradient descent can be very slow. Furthermore it can be impracticable for larger data-sets that don't fit into working memory.
Stochastic gradient descent (SGD)
Stochastic gradient descent (SGD), on the other hand, performs a parameter update for each training example
Batch gradient descent performs redundant gradient computations as it recomputes gradients for similar examples before performing a parameter update. SGD doesn't have the same redundancy as it updates for each training example, which is why it's usually much faster than batch gradient descend. Furthermore, it can also be used for online learning.
Performing a parameter update with only one training example can lead to high variance, which can cause the objective function to fluctuate.
Mini-batch gradient descent
Mini-batch gradient descent combines the advantages of SGD and batch gradient descent by performing parameter updates for every mini-batch of
By performing the parameter update on a mini-batch, it a) reduces the variance of the update, which can lead to more stable convergence, and b) can make use of highly optimized matrix calculates commonly found in state-of-the-art deep learning libraries.
The mini-batch size usually ranges between 16 and 256 depending on the application and the training hardware. Mini-batch gradient descent is typically the algorithm of choice from the three ones discussed above.

Challenges
All three of the above-mentioned types of Gradient descent have a few challenges that need to be addressed:
- Choosing a proper learning rate can be difficult.
- The learning rate is the same throughout training.
- The same learning rate is applied to all parameter updates.
- Gradient Descent is a first-order optimization algorithm. Meaning that it only takes into account the first derivative of the objective function and not the second derivative, even though the curvature of the objective function also affects the size of each learning step.
Momentum
Momentum is a method that helps accelerate SGD in the relevant direction and dampens oscillations by adding a fraction
The momentum term increases for dimensions where gradients continuously point in the same directions and reduces the updates for dimensions whose gradients change directions from one time step to another. As a result, convergence is faster, and oscillation is reduced.

Nesterov accelerated gradient
Nesterov accelerated gradient (NAG), also called Nesterov Momentum is a variation of momentum that approximates the next values of the parameters by computing
Momentum first computes the current gradient (small blue vector) and then takes a big jump in the direction of the updated accumulated gradient (big blue vector). NAG, on the other hand, first makes a big jump in the direction of the previous accumulated gradient (brown vector), measures the gradient, and then makes a correction (red vector), which results in the green vector. The anticipation prevents the update from overshooting and results in increased responsiveness.

Code
Resources
- An overview of gradient descent optimization algorithms
- Gradient Descent ML Glossary
- Gradient Descent Algorithm and Its Variants
- Gradient Descent, Step-by-Step
- Stochastic Gradient Descent, Clearly Explained!!!
- Gradient descent, how neural networks learn | Deep learning, chapter 2
- Lecture 6a Overview of mini-batch gradient descent