Adaptive Moment Estimation (Adam)
Published on: July 18, 2021
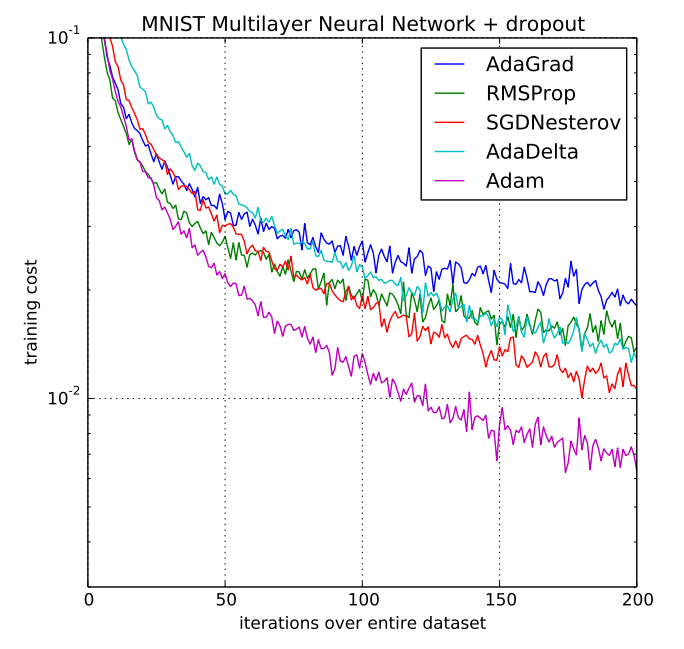
Table of Content
Adaptive Moment Estimation better known as Adam is another adaptive learning rate method first published in 2014 by Kingma et. al. [1] In addition to storing an exponentially decaying average of past squared gradients
To counteract the biases by calculating bias-corrected first and second moment esimates:
As default values for
[1] Diederik P. Kingma and Jimmy Ba (2014). Adam: A Method for Stochastic Optimization.
[2] Sebastian Ruder (2016). An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747.