Adagrad
Published on: June 22, 2021
Adagrad [1] is a gradient-based optimization algorithm that adaptively scales the learning rate to the parameters, performing smaller updates for parameters associated with frequently occurring features and larger updates for parameters associated with infrequent features eliminating the need to tune the learning rate manually. The above-mentioned behavior makes Adagrad well-suited for dealing with sparse data, and Dean et al. [2] have found out that Adagrad is much more robust than SGD.
Reminder: The SDG update for each parameter
To scale the learning rate to each parameter Adagrad modifies the learning rate
Here
The above can be vectorized as follows:
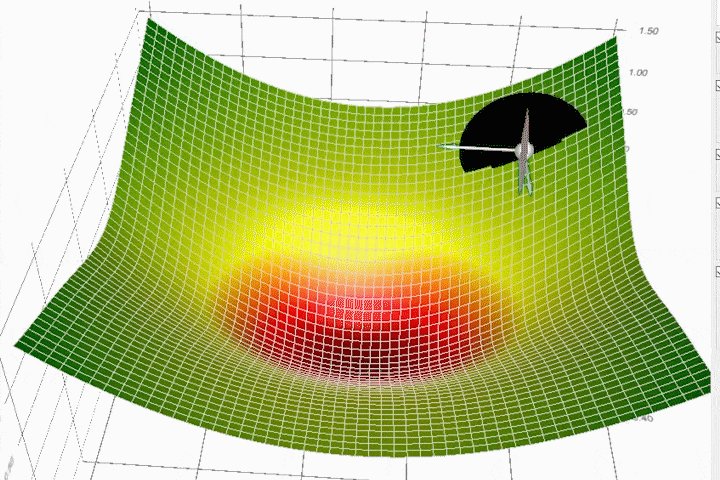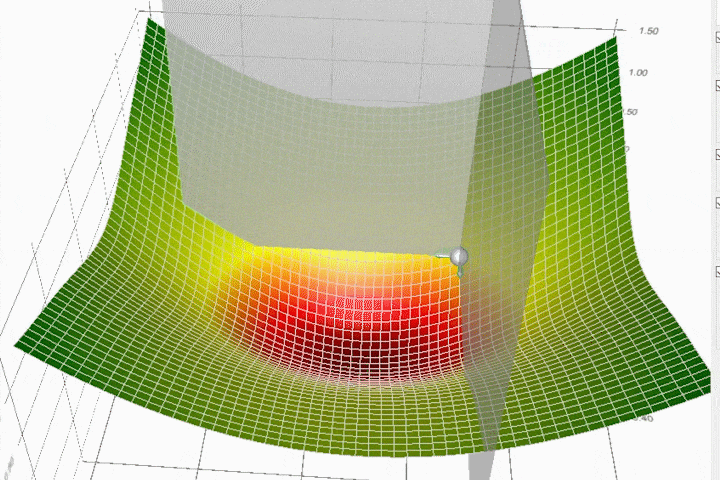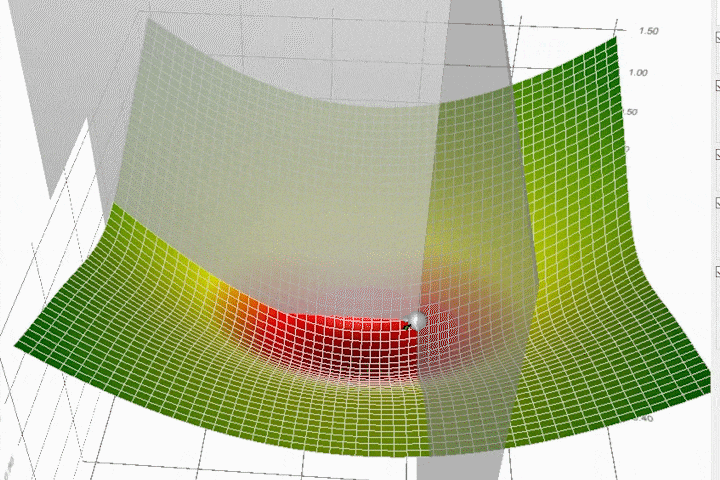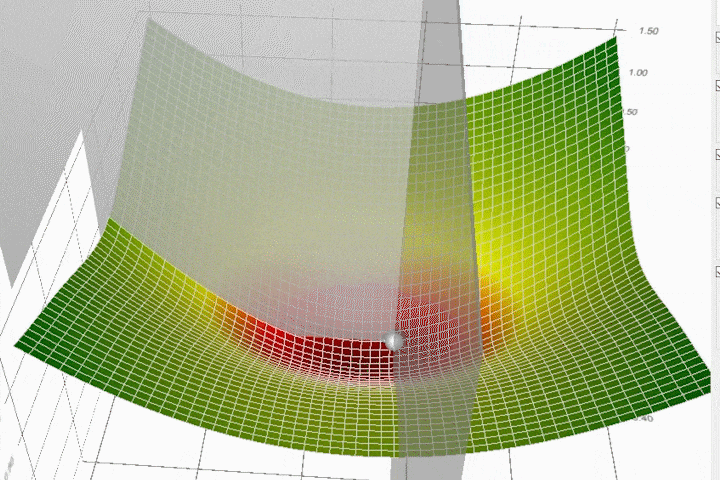
Adagrads most significant benefit is that it eliminates the need to tune the learning rate manually, but it still isn't perfect. Its main weakness is that it accumulates the squared gradients in the denominator. Since all the squared terms are positive, the accumulated sum keeps on growing during training. Therefore the learning rate keeps shrinking as the training continues, and it eventually becomes infinitely small. Other algorithms like Adadelta, RMSprop, and Adam try to resolve this flaw. [3]
[1] Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121–2159. Retrieved from [http://jmlr.org/papers/v12/duchi11a.html](http://jml
[2] Dean, J., Corrado, G. S., Monga, R., Chen, K., Devin, M., Le, Q. V, … Ng, A. Y. (2012). Large Scale Distributed Deep Networks. NIPS 2012: Neural Information Processing Systems, 1–11. [http://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf](http://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf)
[3] Sebastian Ruder (2016). An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747.