ADADELTA: An Adaptive Learning Rate Method
Published on: July 10, 2021
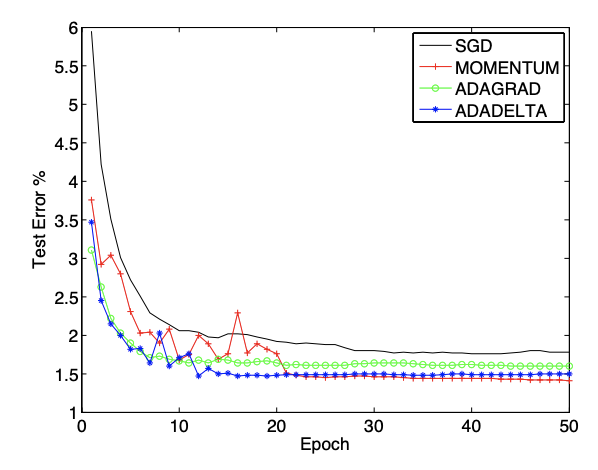
Adadelta is a stochastic gradient-based optimization algorithm that allows for per-dimension learning rates. Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to a fixed size
Instead of inefficiently storing
AdaDelta takes the form:
The authors that the units in the weight update don't match, i.e., the update should have the same hypothetical units as the parameters/weights. To realize this, they use the root mean squared error of parameter updates.
Since
For more information on how to derive this formula, take a look at 'An overview of gradient descent optimization algorithms' by Sebastian Ruder and the original Adadelta paper by Matthew D. Zeiler.
Adadelta's main advantages over Adagrad are that it doesn't need a default learning rate and that it doesn't decrease the learning rate as aggressively and monotonically as Adagrad.
[1] Sebastian Ruder (2016). An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747.
[2] https://paperswithcode.com/method/adadelta